Kubernetes Scaling
- Target functionality
- Why do it this way?
- How to achieve it
Target Functionality
- Autoscale EC2 instances on CPU & memory reservation (Limit and Request)
- Containers scale independently from EC2 instances
- All containers must reserve CPU & memory
- Spot instances, including production
Why?
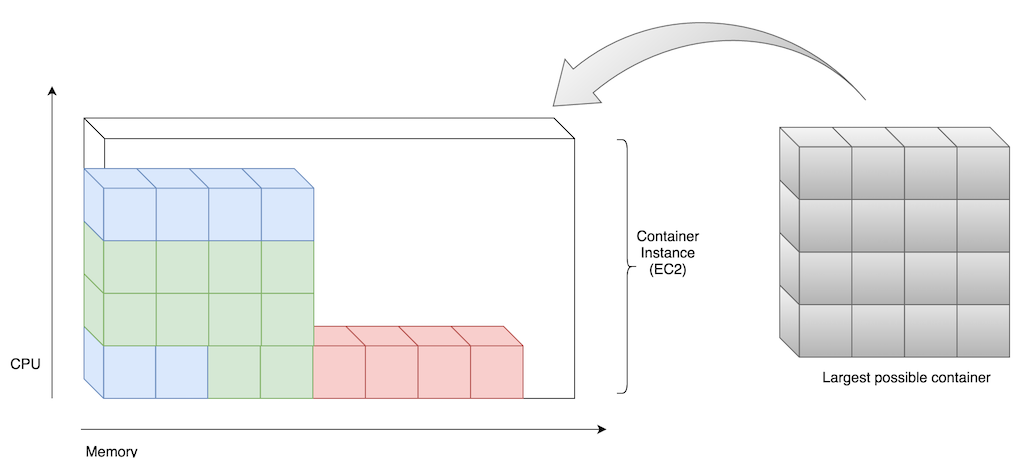
- Complete abstraction: PaaS
- Autoscale mixed workloads arbitrarily
- Reliable multitenancy for apps
- Free chaos engineering with spot instances
Implementation
- RangeLimit
- cluster-autoscaler
- Spot instances
- kube-spot-termination-notice-handler
RangeLimit
---
apiVersion: v1
kind: LimitRange
metadata:
name: default-limit-range
spec:
limits:
- default:
memory: 512Mi
defaultRequest:
cpu: 250m
type: Container
cluster-autoscaler
… terrible defaults
sslCertPath: /etc/ssl/certs/ca-certificates.crt # path to SSL cert in CoreOS. Container crashes without it
# https://medium.com/preply-engineering/why-and-how-do-we-run-kubernetes-on-the-spot-instances-c88d32fb9df3
extraArgs:
# Detect similar node groups and balance the number of nodes between them.
# Since we have similar IG per AZ, it's good to switch on this option
balance-similar-node-groups: true
# Algorithm, which autoscaler uses for re-scheduling pods
expander: random
# Since kops configuration allows kube-system pods to go to the all nodes, we need this option in order to downscale the cluster
skip-nodes-with-system-pods: "false"
# https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#how-can-i-configure-overprovisioning-with-cluster-autoscaler
expendable-pods-priority-cutoff: "-10"
# Cluster utilisation will be poor with default values
scale-down-utilization-threshold: 90
# run on master where additional IAM permissions are
nodeSelector:
kubernetes.io/role: master
tolerations:
- key: node-role.kubernetes.io/master
operator: "Exists"
effect: "NoSchedule"
rbac:
create: true
kops
apiVersion: kops/v1alpha2
kind: Cluster
metadata:
creationTimestamp: 2018-09-18T06:53:45Z
name: ${KUBE_CLUSTER_NAME}
spec:
additionalPolicies:
master: |
[
{"Effect":"Allow","Action":["autoscaling:DescribeAutoScalingGroups","autoscaling:DescribeAutoScalingInstances","autoscaling:DescribeLaunchConfigurations","autoscaling:DescribeTags","autoscaling:SetDesiredCapacity","autoscaling:TerminateInstanceInAutoScalingGroup"],"Resource":"*"}
]
...
kops continued…
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
labels:
kops.k8s.io/cluster: ${KUBE_CLUSTER_NAME}
name: nodes-c4
spec:
image: coreos.com/CoreOS-stable-1855.5.0-hvm
machineType: c4.xlarge
maxPrice: "0.5" # indicates spot
minSize: 0
maxSize: 10
nodeLabels:
kops.k8s.io/instancegroup: nodes
spot: "true"
cloudLabels:
k8s.io/cluster-autoscaler/enabled: ""
kubernetes.io/cluster/${KUBE_CLUSTER_NAME}: ""
role: Node
subnets:
- ap-southeast-2a
- ap-southeast-2b
- ap-southeast-2c
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
labels:
kops.k8s.io/cluster: ${KUBE_CLUSTER_NAME}
name: nodes-m4
spec:
image: coreos.com/CoreOS-stable-1855.5.0-hvm
machineType: m4.xlarge
maxPrice: "0.5" # indicates spot
minSize: 0
maxSize: 10
nodeLabels:
kops.k8s.io/instancegroup: nodes
spot: "true"
cloudLabels:
k8s.io/cluster-autoscaler/enabled: ""
kubernetes.io/cluster/${KUBE_CLUSTER_NAME}: ""
role: Node
subnets:
- ap-southeast-2a
- ap-southeast-2b
- ap-southeast-2c
apiVersion: kops/v1alpha2
kind: InstanceGroup
metadata:
labels:
kops.k8s.io/cluster: ${KUBE_CLUSTER_NAME}
name: nodes-c5
spec:
image: coreos.com/CoreOS-stable-1855.5.0-hvm
maxPrice: "0.5" # indicates spot
machineType: c5.xlarge
minSize: 1
maxSize: 10
nodeLabels:
kops.k8s.io/instancegroup: nodes
spot: "true"
cloudLabels:
k8s.io/cluster-autoscaler/enabled: ""
kubernetes.io/cluster/${KUBE_CLUSTER_NAME}: ""
role: Node
subnets:
- ap-southeast-2a
- ap-southeast-2b
- ap-southeast-2c
kube-spot-termination-notice
Done!
Our k8s cluster now:
- Will scale consistently on mixed workloads
- Has reduced costs thanks to spot instances
- Will drain pods before an instance is terminated
Next
- Overprovisioning
- Kubernetes metrics-server
- Horizontal Pod Autoscaler (HPA)
- Prometheus Operator & Prometheus metrics-server adapter